Variational Inference
Last updated at 03-06-2018
It took me more than two weeks to finally to get the essence of variational inference. The painful but fulfilling process brought me to appreciate the really difficult (at least for me) but beautiful math behind it.
![]() A couple of useful tutorials I found:
A couple of useful tutorials I found:
-
D. M. Blei, A. Kucukelbir, and J. D. McAuliffe, “Variational Inference: A Review for Statisticians,” J. Am. Stat. Assoc., vol. 112, no. 518, pp. 859–877, 2017.
-
D. G. Tzikas, A. C. Likas and N. P. Galatsanos, “The variational approximation for Bayesian inference,” in IEEE Signal Processing Magazine, vol. 25, no. 6, pp. 131-146, November 2008. doi: 10.1109/MSP.2008.929620
-
https://am207.github.io/2017/wiki/VI.html
-
Machine Learning: Variational Inference by Jordan Boyd-Graber
Table of Contents
- Introduction
- Evidence Lower Bound (ELBO)
- Mean Field Variational Family
- Coordinate Ascent VI (CAVI)
- Applying VI on GMM
import numpy as np
import scipy as sp
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
Introduction
A motivating example
As with expectation maximization, I start by describing a problem to motivate variational inference. Please refer to Prof. Blei’s review for more details above.
Let’s start by considering a problem where we have data points sampled from mixtures of Gaussian distributions. Specifically, there are $K$ univariate Gaussian distributions with means $\mathbf{\mu} = { \mu_1, …, \mu_K }$ and unit variance ($\mathbf{\sigma}=\mathbf{1}$) (for simplicity):
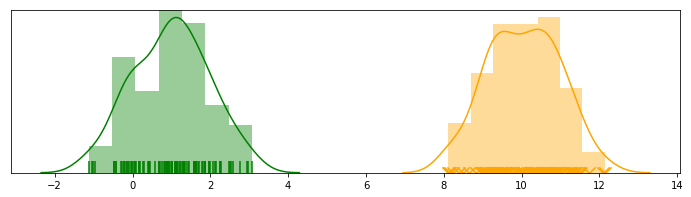
Please refer to my EM post on details of this sample data
In a Bayesian setting, we can assume that all the means come from the same prior distribution, which is also a Gaussian $\mathcal{N}(0, \sigma^2)$, with variance $\sigma^2$ being a hyperparameter. Specifically, we can setup a very simple generative model:
- For each data point $x^{(i)}$, where $i=1,…,n$
- Sample a cluster assigment (or membership to which Gaussian mixture component it belongs) $c^{(i)}$ uniformally: $c^{(i)} \sim Uniform(K)$
- Sample its value from the correpsonding component: $x^{(i)} \sim \mathcal{N}(\mu_{c_i}, 1)$
This gives us a straightforward view of how the joint probability can be written out:
Summing/integrating out the latent variables, we can obtain the marginal likelihood (i.e., evidence):
Note that while it is possible to compute individual termins within the integral (Gaussian prior and Gaussian likelihood), the overall complexity will go up to $\mathcal{O}(K^n)$ (which is all possible configurations). Therefore, we need to consider approximate inference due to the intractability.
General situation
Actually, the motivation of VI is very similar to EM, which is to come up with an approximation of point estimates of the latent variables. Instead of point estimates, VI tries to find variational distributions that serve as good proxies for the exact solution.
Suppose we have $\mathbf{z}={ z^{(1)}, …, z^{(n)}}$ as observed data and $\mathbf{z}={ z^{(1)}, …, z^{(n)}}$ as latent variables. The inference problem is to find the posterior probability of the latent variables given observations $p(\mathbf{z} \vert \mathbf{x})$:
Often times, the denominator evidence is intractable. Therefore, we need approximations to find a relatively good solution in a reasonable amount of time. VI is exactly what we need!
Evidence Lower Bound (ELBO)
In my EM post, we can prove that the log evidence $ln~p(\mathbf{x})$ can actually be decomposed as follows (note that we will use integral this time):
where $\mathcal{L}(\mathbf{x})$ is defined as ELBO: KL divergence is bounded and nonnegative.
If we further decompose ELBO, we have:
The last equation above shows that ELBO trades off between the two terms:
- The first term prefers $q(\mathbf{z})$ to be high when complete likelihood $p(\mathbf{x}, \mathbf{z})$ is high
- The second term encourages $q(\mathbf{z})$ to be diffuse across the space
Finally, we note that, in EM, we are able to compute $p(\mathbf{z}\vert \mathbf{x})$ so that we can easily maximize ELBO. However, VI is the way to do when we cannot.
Mean Field Variational Family
By far, we haven’t say anything about what $q$’s should be. In this note, we only look at a classical type, called mean field variational family. Specifically, it assumes that latent variables are mutually independent. This means that we can easily factorize the variational distributions into groups:
By doing this, we are unable to capture the interdependence between the latent variables. A nice visualization from Blei et al. (2017):

Coordinate Ascent VI (CAVI)
By factorizing the variational distributions into invidual products, we can easily apply coordinate ascent optimization on each factor. A common procedure to conduct CAVI is:
- Choose variational distributions $q$;
- Compute ELBO;
- Optimize individual $q_j$’s by taking the gradient for each latent variable;
- Repeat until ELBO converges.
Derivation of optimal var. dist.:
In fact, we can derive the optimal solutions without too much efforts:
Now, according to the definition of expectation, we have:
We assume independence between latent variables’ variational distributions $q(z)$
Therefore we have:
We can see that the first two terms can be combined into a negative KL divergence between those within the $E_j\big[ \cdot \big]$. Therefore, we can write down the optimal solution as:
Alternative way
While the derivation through iterative expectation seems to be simpler, I personally still prefer taking partial derivatives to parameters of variational distributions, as in the following example, which seems to be more natural to me. After all, we will be using ELBO to check convergence anyway.
Applying VI on GMM
Let’s get back to our original problem with the univariate Gaussian mixtures with unit variance. The full parameterization is as follows:
Note that $c_i$ is a vector of one’s and zero’s such that $c_{ij} = 1; c_{il} = 0 \text{ for } j\neq l$ (a.k.a, one-hot vector).
By mean field VI, we can introduce variational distributions for the two latent variables $\mathbf{c}$ and $\mathbf{\mu}$:
Choose $q$
According to what we have above, we will choose the following variational distributions for $c$ and $\mu$
where:
Therefore, $\phi_i$ is a vector of probabilities such that $p(c_i=j) = \phi_{ij}$
ELBO
The most important thing is to write down ELBO, the evidence lower bound, which is needed for (i) parameter updates; (ii) convergence check. However, I’ve seen that convergence check could be done by the relative change of parameter estimates here. If parameters do not change much, VI will stop by thinking that it has converged.
Recall that $ELBO = E_q[log~p(x,z)] - E_q[log~q(z)] $. Let me split this task into two.
Full joint probability
The hidden/latent variables in this problem are $c$ and $\mu$.
$p(c_i) = \dfrac{1}{K}$ is a constant drop it. We then expand $p(\mu_j)$:
For $log~p(x_i~\vert~c_i, \mu)$, it is a bit tricky. Recall that $c_i$ is a one-hot vector, where only one of the element is 1. We can make use of this property and rewrite:
Combine all the above, we can write the log full joint probability as:
Entropy of variational distributions
Thanks to the mean field assumption, we can factorize the joint of variational easily:
Let’s expand these two terms seperately.
Therefore, we have:
Full ELBO
Merge the results back, we have the ELBO written as:
Parameter updates
$\phi_{ij}$
This is a contrained optimization because $\sum_j \phi_{ij} = 1~\forall i$. However, we do not need to add the Lagrange multiplier and the result can still be normalized (we are using a lot of $\propto$ here!)
$m_j$
$s_j^2$
Note that we are considering $s_j^2$ as a whole.
Now that we have the ELBO and paramter update formulas, we can setup our own VI algorithm for this simple Guassian Mixture!
Python Implementation
import numpy as np
class UGMM(object):
'''Univariate GMM with CAVI'''
def __init__(self, X, K=2, sigma=1):
self.X = X
self.K = K
self.N = self.X.shape[0]
self.sigma2 = sigma**2
def _init(self):
self.phi = np.random.dirichlet([np.random.random()*np.random.randint(1, 10)]*self.K, self.N)
self.m = np.random.randint(int(self.X.min()), high=int(self.X.max()), size=self.K).astype(float)
self.m += self.X.max()*np.random.random(self.K)
self.s2 = np.ones(self.K) * np.random.random(self.K)
print('Init mean')
print(self.m)
print('Init s2')
print(self.s2)
def get_elbo(self):
t1 = np.log(self.s2) - self.m/self.sigma2
t1 = t1.sum()
t2 = -0.5*np.add.outer(self.X**2, self.s2+self.m**2)
t2 += np.outer(self.X, self.m)
t2 -= np.log(self.phi)
t2 *= self.phi
t2 = t2.sum()
return t1 + t2
def fit(self, max_iter=100, tol=1e-10):
self._init()
self.elbo_values = [self.get_elbo()]
self.m_history = [self.m]
self.s2_history = [self.s2]
for iter_ in range(1, max_iter+1):
self._cavi()
self.m_history.append(self.m)
self.s2_history.append(self.s2)
self.elbo_values.append(self.get_elbo())
if iter_ % 5 == 0:
print(iter_, self.m_history[iter_])
if np.abs(self.elbo_values[-2] - self.elbo_values[-1]) <= tol:
print('ELBO converged with ll %.3f at iteration %d'%(self.elbo_values[-1],
iter_))
break
if iter_ == max_iter:
print('ELBO ended with ll %.3f'%(self.elbo_values[-1]))
def _cavi(self):
self._update_phi()
self._update_mu()
def _update_phi(self):
t1 = np.outer(self.X, self.m)
t2 = -(0.5*self.m**2 + 0.5*self.s2)
exponent = t1 + t2[np.newaxis, :]
self.phi = np.exp(exponent)
self.phi = self.phi / self.phi.sum(1)[:, np.newaxis]
def _update_mu(self):
self.m = (self.phi*self.X[:, np.newaxis]).sum(0) * (1/self.sigma2 + self.phi.sum(0))**(-1)
assert self.m.size == self.K
#print(self.m)
self.s2 = (1/self.sigma2 + self.phi.sum(0))**(-1)
assert self.s2.size == self.K
Making data
num_components = 3
mu_arr = np.random.choice(np.arange(-10, 10, 2),
num_components) +\
np.random.random(num_components)
mu_arr
array([ 8.79153551, 6.29803456, -5.7042636 ])
SAMPLE = 1000
X = np.random.normal(loc=mu_arr[0], scale=1, size=SAMPLE)
for i, mu in enumerate(mu_arr[1:]):
X = np.append(X, np.random.normal(loc=mu, scale=1, size=SAMPLE))
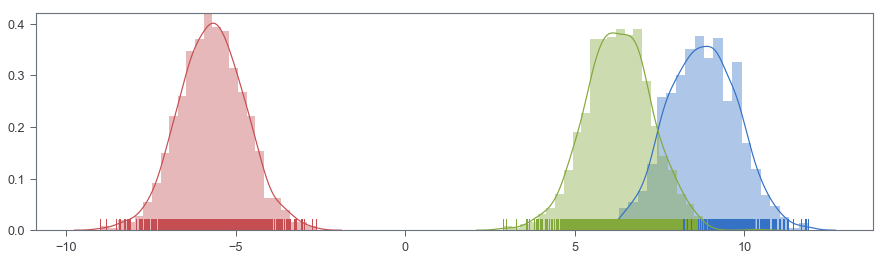
fig, ax = plt.subplots(figsize=(15, 4))
sns.distplot(X[:SAMPLE], ax=ax, rug=True)
sns.distplot(X[SAMPLE:SAMPLE*2], ax=ax, rug=True)
sns.distplot(X[SAMPLE*2:], ax=ax, rug=True)
<matplotlib.axes._subplots.AxesSubplot at 0x10f5784e0>
ugmm = UGMM(X, 3)
ugmm.fit()
Init mean
[9.62056838 2.48053419 8.95455044]
Init s2
[0.22102799 0.50256273 0.72923656]
5 [ 8.78575069 -5.69598804 6.32040619]
10 [ 8.77126102 -5.69598804 6.30384436]
15 [ 8.77083542 -5.69598804 6.30344752]
20 [ 8.77082412 -5.69598804 6.30343699]
25 [ 8.77082382 -5.69598804 6.30343671]
30 [ 8.77082381 -5.69598804 6.3034367 ]
35 [ 8.77082381 -5.69598804 6.3034367 ]
ELBO converged with ll -1001.987 at iteration 35
ugmm.phi.argmax(1)
array([0, 0, 0, ..., 1, 1, 1])
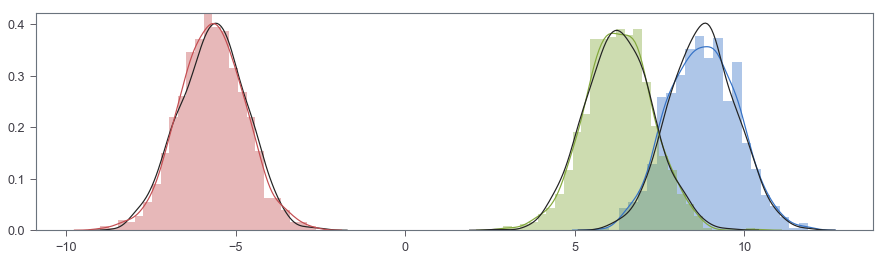
sorted(mu_arr)
[-5.704263600460798, 6.298034563379406, 8.791535506275245]
sorted(ugmm.m)
[-5.695988039984863, 6.303436701203107, 8.770823807705389]
fig, ax = plt.subplots(figsize=(15, 4))
sns.distplot(X[:SAMPLE], ax=ax, hist=True, norm_hist=True)
sns.distplot(np.random.normal(ugmm.m[0], 1, SAMPLE), color='k', hist=False, kde=True)
sns.distplot(X[SAMPLE:SAMPLE*2], ax=ax, hist=True, norm_hist=True)
sns.distplot(np.random.normal(ugmm.m[1], 1, SAMPLE), color='k', hist=False, kde=True)
sns.distplot(X[SAMPLE*2:], ax=ax, hist=True, norm_hist=True)
sns.distplot(np.random.normal(ugmm.m[2], 1, SAMPLE), color='k', hist=False, kde=True)

Zhiya Zuo
Filet-O-Fish 🍔 is the BEST!