MLE vs. MAP
Table of Contents
import numpy as np
import scipy as sp
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
Motivation
While I am happily (and painfully ![]() ) learning mean field variational inference, I suddenly found that I am not 100% sure about the differences between maximum likelihood estimation (MLE), maximum a posteriori (MAP), expectation maximization (EM), and variational inference (VI). It turns out that they are easy to distinguish after searching here and there!
) learning mean field variational inference, I suddenly found that I am not 100% sure about the differences between maximum likelihood estimation (MLE), maximum a posteriori (MAP), expectation maximization (EM), and variational inference (VI). It turns out that they are easy to distinguish after searching here and there!
In this study note here, I will only focus on MLE vs. MAP because they are very similar. In fact, as we can see later, MLE is a special case of MAP, where a uniform prior is used.
TL;DR
- MLE produces a point estimate that maximizes likelihood function of the unknow parameters given observations (i.e., data)
- MAP is a generalized case of MLE. It also produces a point estimate, which is the mode of the posterior distribution of the parameters
- EM is an iterative method that tries to find MLE/MAP estimates of parameters when marginal probability is intractable (e.g., when there’re missing data or latent variables)
- VI is a Bayesian method that provides a posterior distribution over the parameters instead of point estimates.
Coin toss
Most tutorials on MLE/MAP start with coin toss because it is a simple yet useful example to explain this topic.
Suppose that we have a coin but we do not know if it is fair not. In other words, we have no idea whether the probability of getting head (H) is the same as tail (T). In this case, how can we estimate such probability?
A natural way to do this is to flip this coin for several times to see how many H’s and T’s do we have. Let’s go with a random experiment. Before we start the experiment, let’s define some notations:
- $X$: a random variable that represents the coin toss outcome ($1$ for
Hand $0$ forT) - $\theta$: the probability of getting
H
Now, let’s assume that we don’t know $\theta$ (here, we will use $\theta=0.7$) and we are going to use random number generator to get some samples and see what the data is like. Let’s start by flip the coin 10 times.
n = 10
theta = 0.7
X_arr = np.random.choice([0, 1], p=[1-theta, theta], size=10)
X_arr
array([1, 1, 0, 1, 0, 1, 1, 1, 1, 1])
We get 8 H’s and 2 T’s. Intuitively, we will do the following calculation even if we are not statisticians:
This seems to be a reasonable guess. But why?
MLE
In fact, $\hat{\theta}$ is exactly what we get by using MLE! In the context of a coin toss, we can use Bernoulli distribution to model $x$:
MLE states that our best guess (techinically, estimation) for $\theta$ based on observations we have. Specifically, such $\theta$ should be maximizing the likelihood function $L(\theta;x)$. That’s also why this method is named maximum likelihood estimation.
Concretely, in our example, we can write down the probability mass function of $x$ to be:
What’s likelihood function then? It is actually just the equation above. However, instead of thinking $p(x)$ as a function of $x$, we think of it as a function of $\theta$, given the data:
In the case where we have more than one experiments (say $x={x_1, …, x_n}$) and assume independence between individual coin tosses, we have the following likelihood:
Most of the time, we will apply logarithm on $L$ for simplicity of computation:
Now this has become an optimization problem: given observations $x$, how do we maximize $\ell$:
It is not difficult to show that $\ell$ is a concave function. Recall that a function a twice-differentiable $f$ is concave i.f.f. its second derivative is nonnegative (I use the case where we only one Bernoulli experiment but it is very similar when there $n$):
Therefore, we can simply take the derivative of $\ell$ and set $\ell’$ value to zero. The resulting $\theta$ will be the one that maximizes the likelihood function:
Notice that since x_i can only take 0 or 1, we can further let $\sum_i x_i = n_{H}$, which is the total number of heads from all the experiments. And that is, in fact, what we did previously: divide $n_{H}$ by $n$!
MAP
MLE works pretty well in the previous example. However, this is not as intuitive as how human infers something. Typically, our belief on things may vary over time. Specifically, we start with some prior knowledge to draw an initial guess. With more evidence, we can then modify our belief and obtain posterior probability of some events of interest. This is exactly Bayesian statistics.
Note that MAP is not completely Bayesian because it only gives a point estimate
Back to the coin toss example. If our data looks like this:
X_arr = np.ones(n)
X_arr
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
Our MLE will simply be: $\dfrac{n_H}{n} = \dfrac{0}{10} = 0$. However, this probably does not make sense. Intuitively, we will guess, for example, $\theta$ should be a value close to 0.5 (although this is not necessarily true). Therefore, we can introduce a prior distribution for our unknow paramter $p(\theta)$. By doing this, we are actually dragging our estimation towards our prior belief. However, the effects of priors will be gone with increasing data. According to Bayes theorem, we have:
The denominator $p(x)$ is fixed, given $x$ and we can simplify as:
Now let’s rewrite our optimization problem into:
As compared with MLE, MAP has one more term, the prior of paramters $p(\theta)$. In fact, if we are applying a uniform prior on MAP, MAP will turn into MLE ($log~p(\theta) = log~constant$). When we take the logarithm of the objective, we are essentially maximizing the posterior and therefore getting the mode as the point estimate.
Still coin toss!
Let’s reuse our coin toss example:
Now we introduce a prior distribution for $\theta$: $\theta \sim Beta(\alpha, \beta)$. Such choice is because of the fact that our likelihood follows a Bernoulli distribution. The use of Beta prior will turn the posterior into another Beta, thanks to the beautiful property of conjugacy. Let’s proof this below:
Therefore, the posterior of $\theta$ will be updated with more data, slowly departing from the given prior.
From a different perspective, we can think of the hyperparameters $\alpha$ and $\beta$ as pseudo counts that smooth the posterior distribution. For example, we assume there are $\alpha$ success and $\beta$ failures before any data is given. In our example of all 1’s, MAP will drag the MLE estimate of $\hat{\theta}=0$ towards our prior belief that it is probably NOT true that a coin toss will always give a H.
Visualizing MAP
As a last example, let’s see the iterative process of how posterior is updated given new data. Let’s assume the true $\theta$ to be 0.7. Let’s use a non-flat Beta prior with $\alpha=\beta=2$.
alpha = beta = 2
theta = 0.7
n = 50
X_arr = np.random.choice([0, 1], p=[1-theta, theta], size=n)
sum(X_arr) / X_arr.size
0.68
Recall that our posterior is updated as $Beta(\alpha + x_i, \beta + 1 - x_i)$ with every input data $x_i$.
beta_arr = np.asarray([[alpha+sum(X_arr[:i+1]), beta+(i+1-sum(X_arr[:i+1]))] for i in range(X_arr.size)])
beta_arr = np.insert(beta_arr, 0, [alpha, beta], 0)
Let’s see how the posterior changes when we have more data points
beta_X = np.linspace(0, 1, 1000)
my_color = '#2E8B57'
fig, ax_arr = plt.subplots(ncols=4, figsize=(16,4), sharex=True)
for i, iter_ in enumerate([0, 5, 15, 30]):
ax = ax_arr[i]
a, b = beta_arr[iter_]
beta_Y = sp.stats.beta.pdf(x=beta_X, a=a, b=b)
ax.plot(beta_X, beta_Y, color=my_color, linewidth=3)
if a > 1 and b > 1:
mode = (a-1)/(a+b-2)
else:
mode = a/(a+b)
ax.axvline(x=mode, linestyle='--', color='k')
ax.set_title('Iteration %d: $\hat{\\theta}_{MAP}$ = %.2f'%(iter_, mode))
fig.tight_layout()
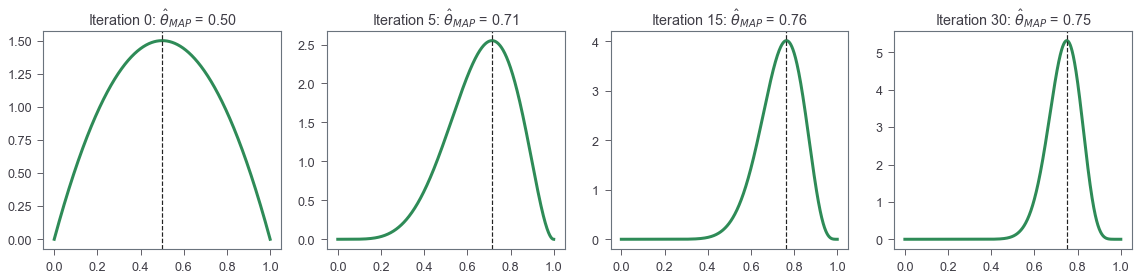
Note that while this example shwos that MAP can give us a whole posterior distribution for paramter $\theta$, the goal of MAP is still to get a point estimate. This simplicified example is easy because we can solve this problem analytically thanks to conjugacy.

Zhiya Zuo
Filet-O-Fish 🍔 is the BEST!